Product Engineer
Chatly Make
One prompt becomes a deployed, committed, thumbnailed app. I cut the round trip ~4× by replacing the agent loop with a pipeline.
Browser · Frontend
Next.jsnginx
:443Engine · FastAPI
:2024Gateway · FastAPI
:8000Turn setup · once
Warm sandbox
cache 600sConcurrent Haiku
Cacheable prompt
~80% offReason ⇄ act · while iterating
Claude Sonnet 4.6 stream
3 retriesTool dispatch
On finish
Git auto-commit
Thumbnail
Done
usageModal Sandbox · remote
tunnels :3000 · :8080Anthropic
Composio
GitHub
Cloudflare R2
Postgres
Supabase
What Chatly Make is, and where it sits
I'm a Product Engineer at Chatly (Vyro.ai). Chatly Make is the part of Chatly's Omni-Agent that turns a single prompt into a running app: it generates the code, commits it to GitHub, deploys the app, makes a preview thumbnail, and wires up connectors. Same spirit as Lovable or bolt.new. Prompt in, deployed app out.
To be clear about scope: I designed and built Make, the app-builder slice, not all of Omni-Agent. Internally it's charon-make. The first DeerFlow-based attempt was charon-df-agent-v1 (the “df” is DeerFlow).
Shipping an app is not writing a report
The first builds were slow: ~45 minutes end to end for a full-stack app, ~20 minutes for frontend-only. That clock covers everything: code generation, GitHub commits, deploy, and thumbnail. For a product meant to feel like “prompt to live app,” 45 minutes isn't a wait. It's an abandon.
Where the time went: engineering reasoning, not instrumented attribution
- Serialized plan, act, observe loop: one model round trip per micro-step, so wall-clock grows roughly linearly with step count. An app touching dozens of files pays that tax dozens of times.
- Cold environments: install and build ran in ad-hoc per-run containers, re-paying the base-image pull and a cold npm/pnpm install every single time.
- Sequential everything: independent files generated one at a time; commit, deploy, and headless-browser thumbnailing all ran back-to-back at the end, latencies stacking instead of overlapping.
- Full-context regeneration: the growing transcript got re-sent each step, so per-step latency climbed as the model re-read code it had already written.
DeerFlow first, then Hermes. Both the wrong shape
I built Make on ByteDance's DeerFlow first. DeerFlow is a deep-research framework: a Coordinator, Planner, Researcher, Coder, Reporter graph tuned for search → read → synthesize → write, with a human-in-the-loop plan-approval gate before execution. Its “Coder” runs Python inside a research flow. It isn't there to scaffold, build, and deploy a real codebase, and the deliverable is a document, not an app. So even simple builds inherited planning overhead, search machinery, and an approval stall that does nothing for autonomous codegen.
Then I tried Hermes: NousResearch's agent framework, the self-improving multi-backend harness, not their LLM models. Better on paper: parallel subagents, a Modal execution backend. But it's still a general long-horizon agent harness. The open-ended loop and per-step inference tax remained, and the defaults are tuned for autonomous task-running, not the tight scaffold → build → preview loop app generation needs.
The honest read: the bottleneck wasn't either framework's quality. An app builder is a mostly-deterministic delivery pipeline wearing an agent costume. So I stopped bending a research harness toward codegen and designed for the actual job.
A pipeline, warm Modal sandboxes, and overlap
I replaced the open-ended loop with an explicit, mostly-deterministic pipeline: scaffold → generate files → install/build → commit → deploy → thumbnail. The model is invoked a bounded number of times for generation instead of once per micro-step, which kills the per-step inference tax and the “should I loop back?” overhead that dominated the research loops.
The redesign. PR titles: “Add pipeline”, “Use modal proxy”
- Warm Modal sandboxes through a thin proxy: build, install, and deploy run in pre-warmed, isolated Linux environments instead of cold per-run Docker. Image-layer cache, a warmed node_modules, and a warm pool mean each app stops re-paying the multi-minute cold install. Untrusted generated code stays sandboxed.
- Execute as you generate: dependency install starts the moment package.json is known, overlapping with continued component generation; coherent files get written and committed while later files are still being produced.
- Parallel codegen: files with no data dependency (separate components, routes, configs) generate concurrently, collapsing a sum of sequential generations toward the cost of the slowest batch.
- Overlapped long tail: thumbnail/screenshot work kicks off on deploy-readiness in a separate worker, so it doesn't block the user-facing deploy. The research/report roles and approval gates are stripped entirely.
About 4×, end to end
Every figure is full end-to-end wall-clock: code generation + GitHub commits + deploy + thumbnail, not just generation.
Full-stack app
~45 min → ~13 min
Frontend-only
~20 min → ~5 min
End-to-end
~4× faster
The clock covers
codegen + commit + deploy + thumbnail
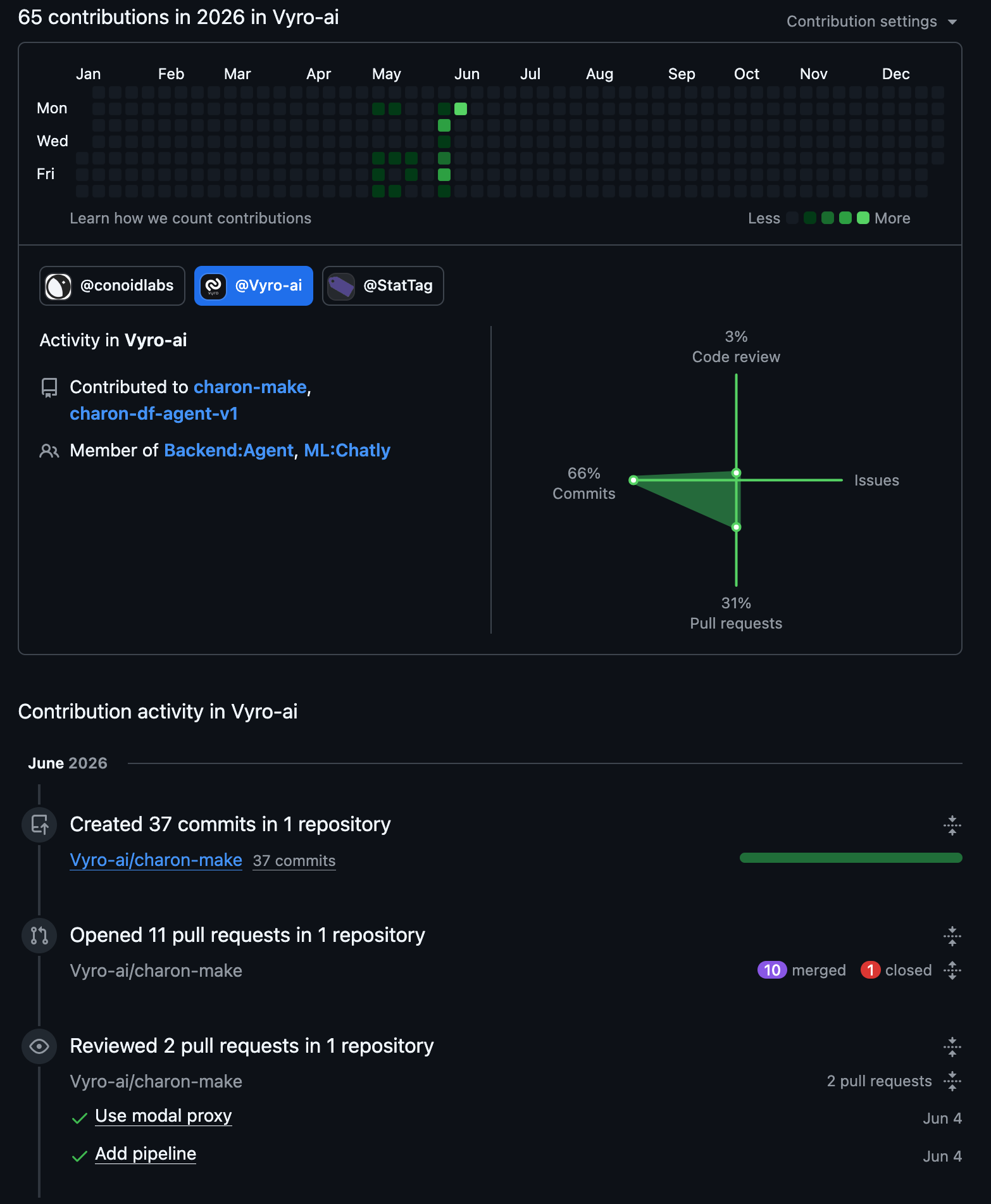
Shipped in
37 commits · 11 PRs · 1 month
Portable lessons
01Match the harness to the job. An app builder is a delivery pipeline, not a research agent.
02Every step that calls the model is on the critical path. Bound the calls; let determinism carry the rest.
03Warm beats clever. A pre-warmed, cached sandbox erases more wall-clock than any prompt trick.
04Overlap is free speed: generate, commit, build, and thumbnail want to run concurrently, not in line.