Distributed Systems + ML
Distributed ML Platform
100 sensors, three models, one stream, no batch. Sub-300ms end to end, on a pipeline that sustains 700+ msg/s.
Sensor data, end to end, in real time.
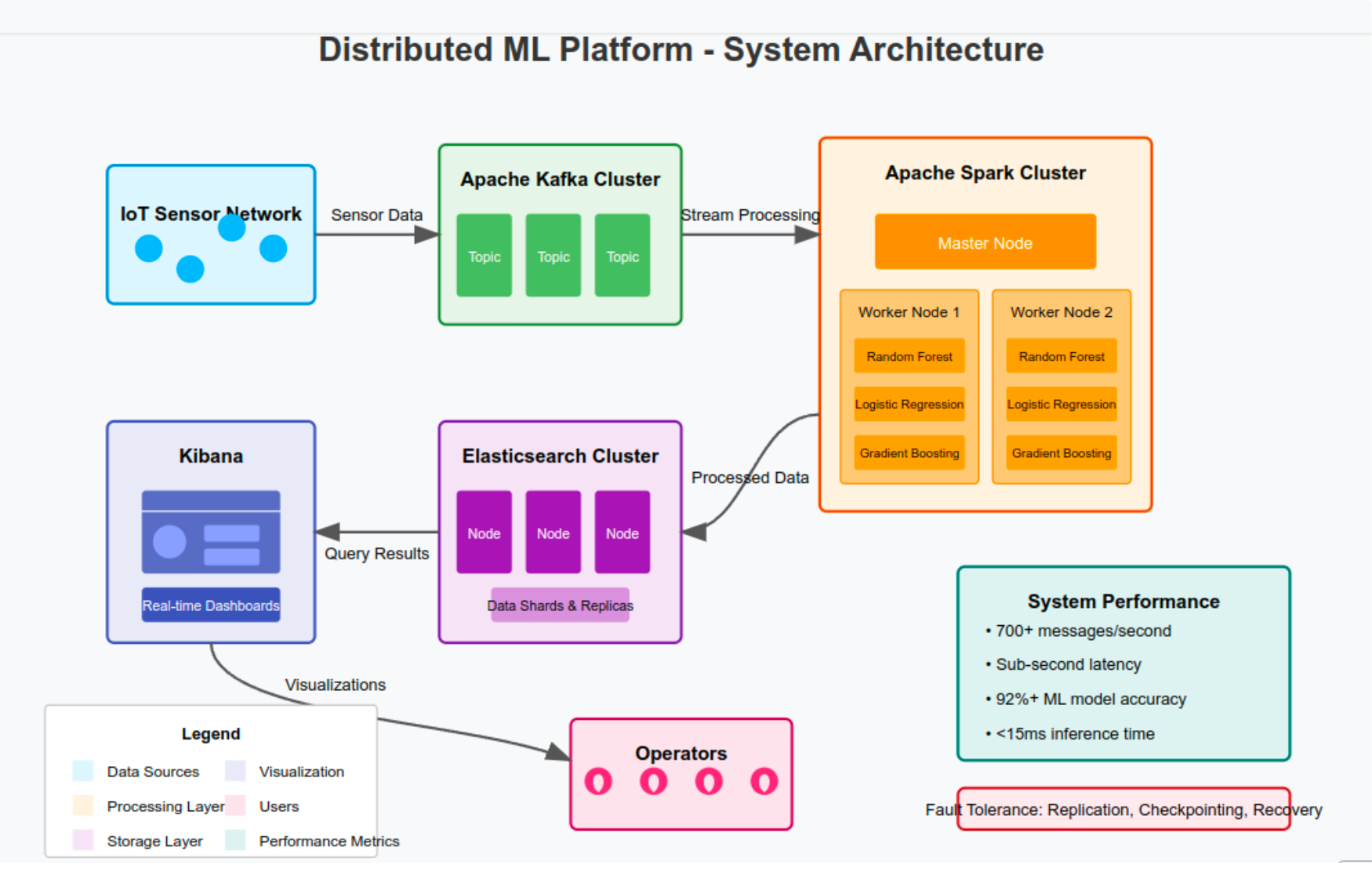
A distributed machine-learning inference and analytics platform for real-time IoT sensor data, built for NUST's Parallel & Distributed Computing course with Ali Abbas. Data is ingested, processed, scored by ML models, and visualized, all as a streaming pipeline.
It combines Apache Kafka for ingestion, Apache Spark Structured Streaming for distributed processing and inference, three MLlib models for analytics, and Elasticsearch + Kibana for live dashboards.
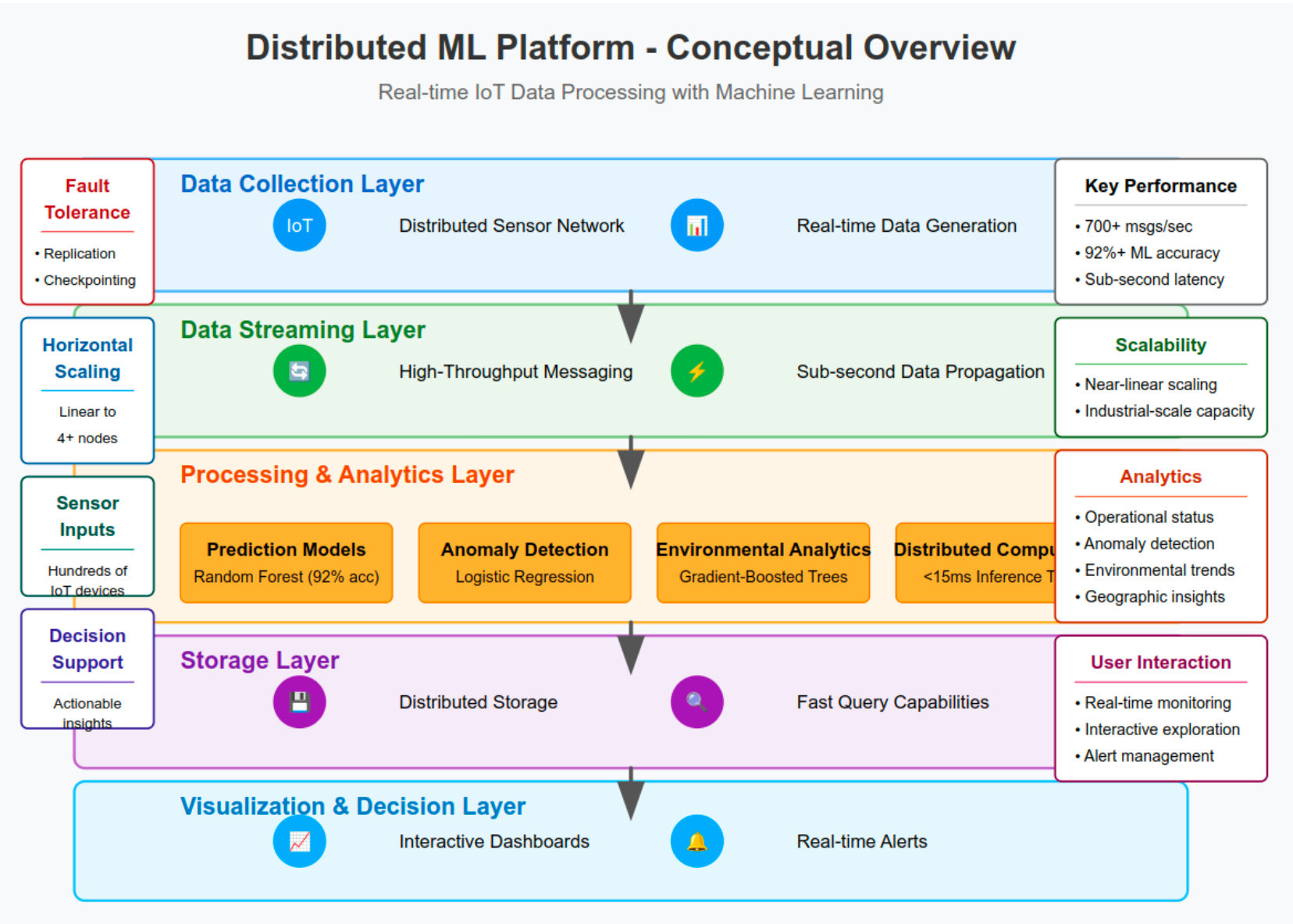
Volume, velocity, and the need for answers now.
IoT sensor networks generate more data, faster, than traditional systems handle: millions of points per second, real-time latency requirements, heterogeneous formats, and a need to turn it all into actionable insight. The architecture has to be horizontally scalable and fault-tolerant from the start.
Kafka → Spark → Elasticsearch → Kibana.
Sensors publish to Kafka, which partitions and replicates for throughput and fault tolerance. Spark Structured Streaming consumes the topics and runs three models in parallel across worker nodes. Scored records land in Elasticsearch (sharded for parallel indexing) and surface in Kibana dashboards. The whole stack is containerized with Docker Compose.
Three models, one stream
- StatusFlagPredictor: a Random Forest classifier for operational status (95.2%, <10ms).
- TemperatureAnomalyDetector: Logistic Regression for anomalies (92.1%, <5ms).
- HumidityRegressor: a Gradient-Boosted Tree regressor (RMSE 2.3, <15ms).
Parallel and fault-tolerant by design
- Data parallelism via Kafka partitioning, Spark RDDs, and Elasticsearch sharding.
- Reliability via Kafka replication, Spark checkpointing, and Elasticsearch replicas.
What it sustained.
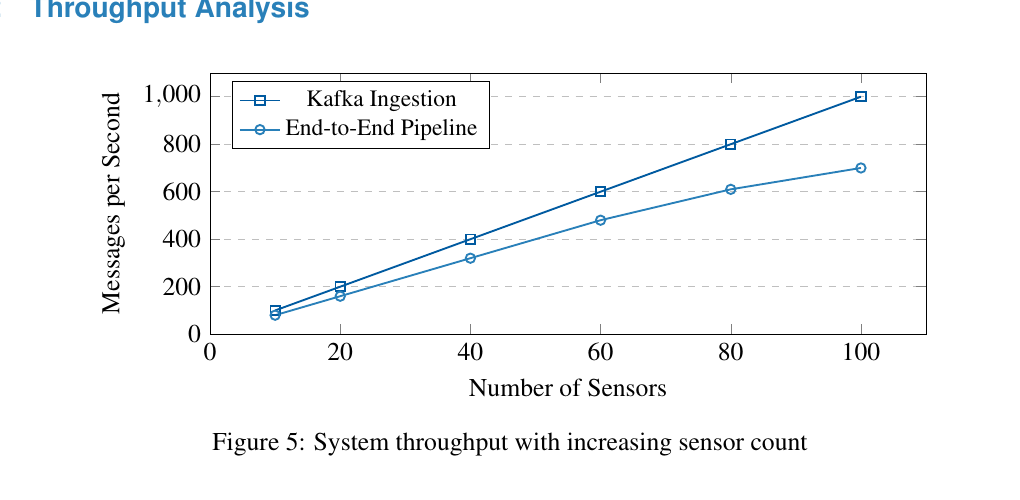
Deployed on a 4-node cluster (8 cores, 16GB RAM each) with 100 simulated sensors at 1 message/second, the platform held linear scalability and sub-second latency end to end.
Full pipeline
700+ msg/s
End-to-end latency
< 300ms
Status accuracy
95.2%
Anomaly accuracy
92.1%
Inference
< 15ms
Cluster
4 nodes · 32 cores
The platform
Streaming pipeline
Kafka ingestion into Spark Structured Streaming with checkpointing.
Parallel ML inference
Three MLlib models scored on every record across worker nodes.
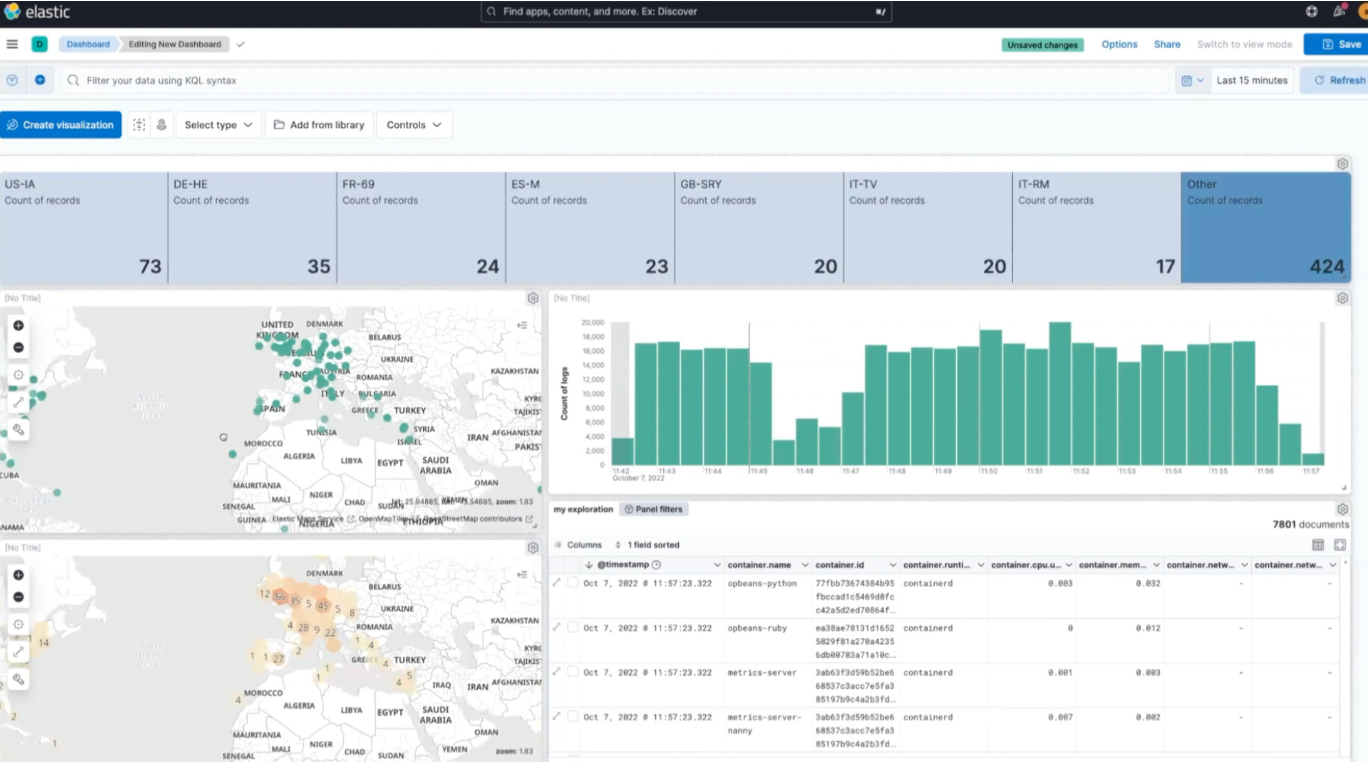
Searchable store
Elasticsearch with sharding and replicas for fast, redundant indexing.
Live dashboards
Kibana views for sensor overview, anomalies, and alert history.
Portable lessons
01Kafka partition sizing decides your throughput ceiling.
02Model complexity is a latency budget. Spend it deliberately.
03Make the pipeline fault-tolerant before you make it fast.