ML Research Engineer · MachVIS Lab
TVFace
2,609,210 faces, 28,955 identities, mined from 22 TV networks. The largest public facial-clustering dataset.

Real faces, at real scale.
TVFace is a large-scale facial-recognition and clustering dataset built at NUST's MachVIS lab: 2,609,210 high-resolution face images of 28,955 unique individuals, extracted from broadcasts across 22 global television networks.
Because the source is live television, the data captures genuine real-world conditions (pose, lighting, expression, and aging over time) instead of the clean, frontal images most datasets rely on.
Benchmarks that don't look like the world.
Facial-recognition research needs scale, diversity, and a realistic long tail. Most public datasets are small, curated, or demographically skewed. Without a benchmark that mirrors real distributions, it's hard to study unsupervised clustering, large-scale recognition, or demographic fairness honestly.
Mine broadcasts, annotate probabilistically.
Faces were detected and clustered from television broadcasts into a natural long-tail distribution, from 10 to 21,983 images per identity, at 224×224 resolution. Each identity carries probabilistic demographic annotations: age, gender, ethnicity (7 groups), expression (7 categories), and head pose.
The dataset ships with a PyTorch-compatible loader and an ethics-first usage framework: research-only, non-commercial, with explicit privacy and bias-mitigation requirements.
The scale of it.
Images
2,609,210
Identities
28,955
Per identity
10 to 21,983
Networks
22 worldwide
Resolution
224 × 224
Size
65 GB
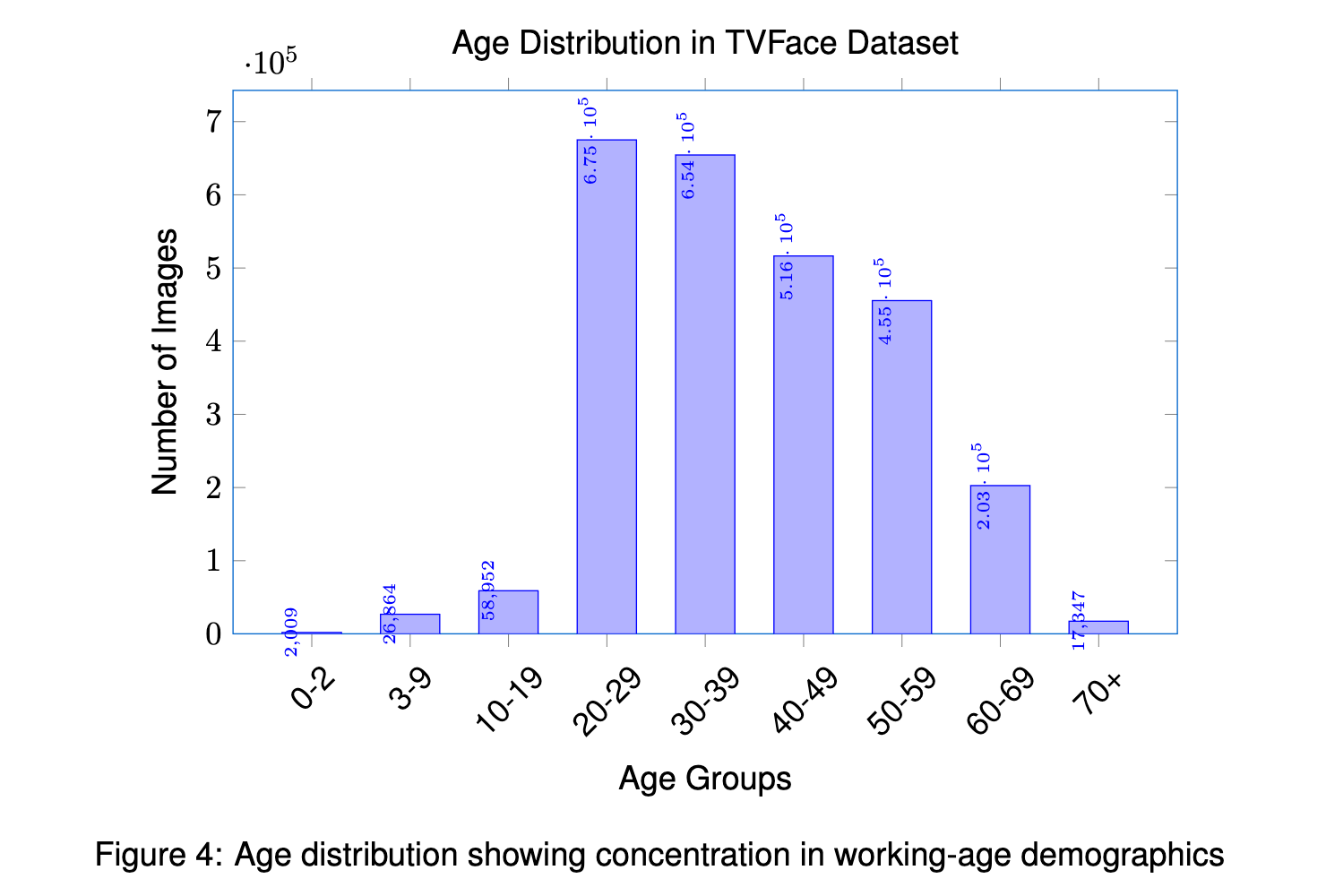
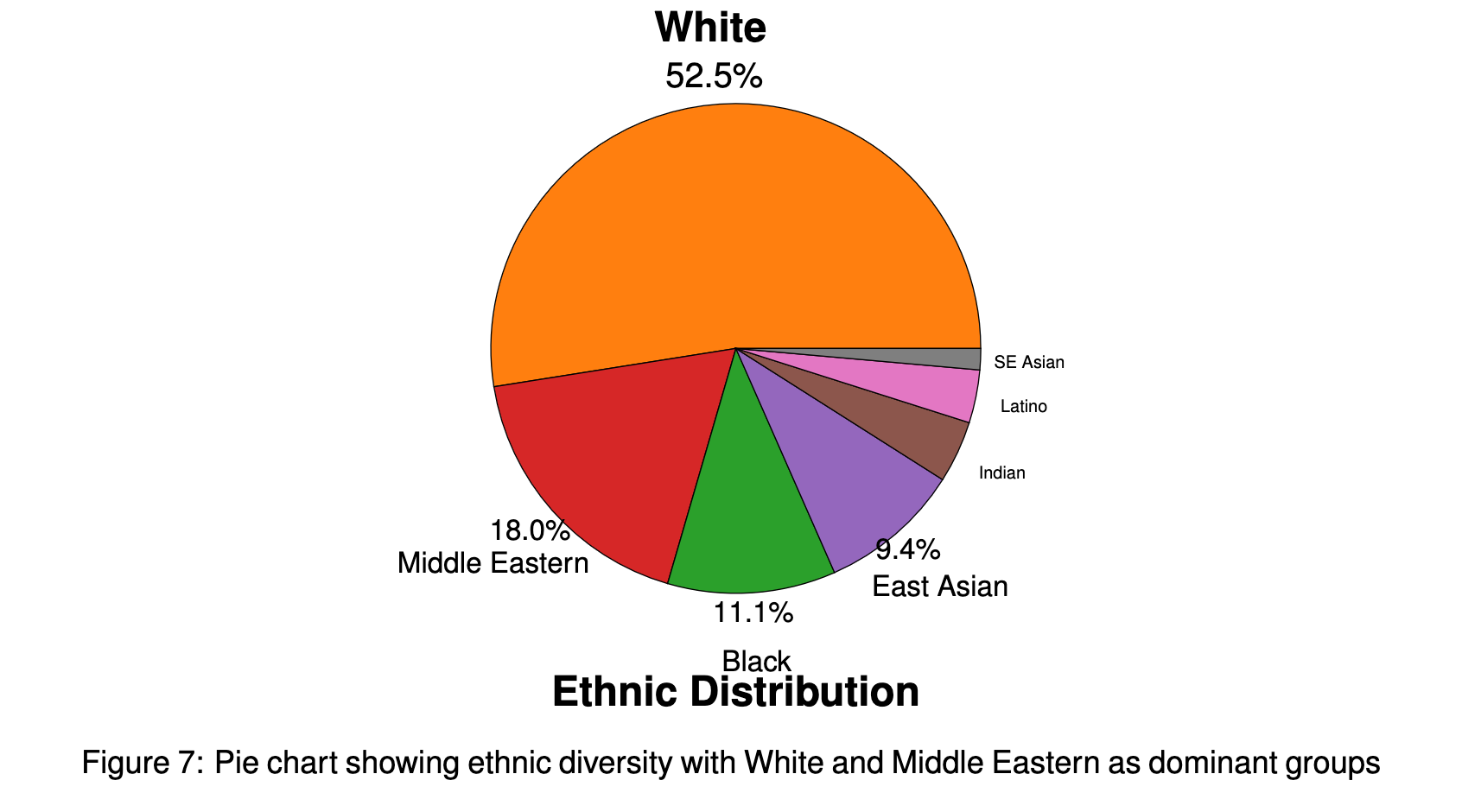
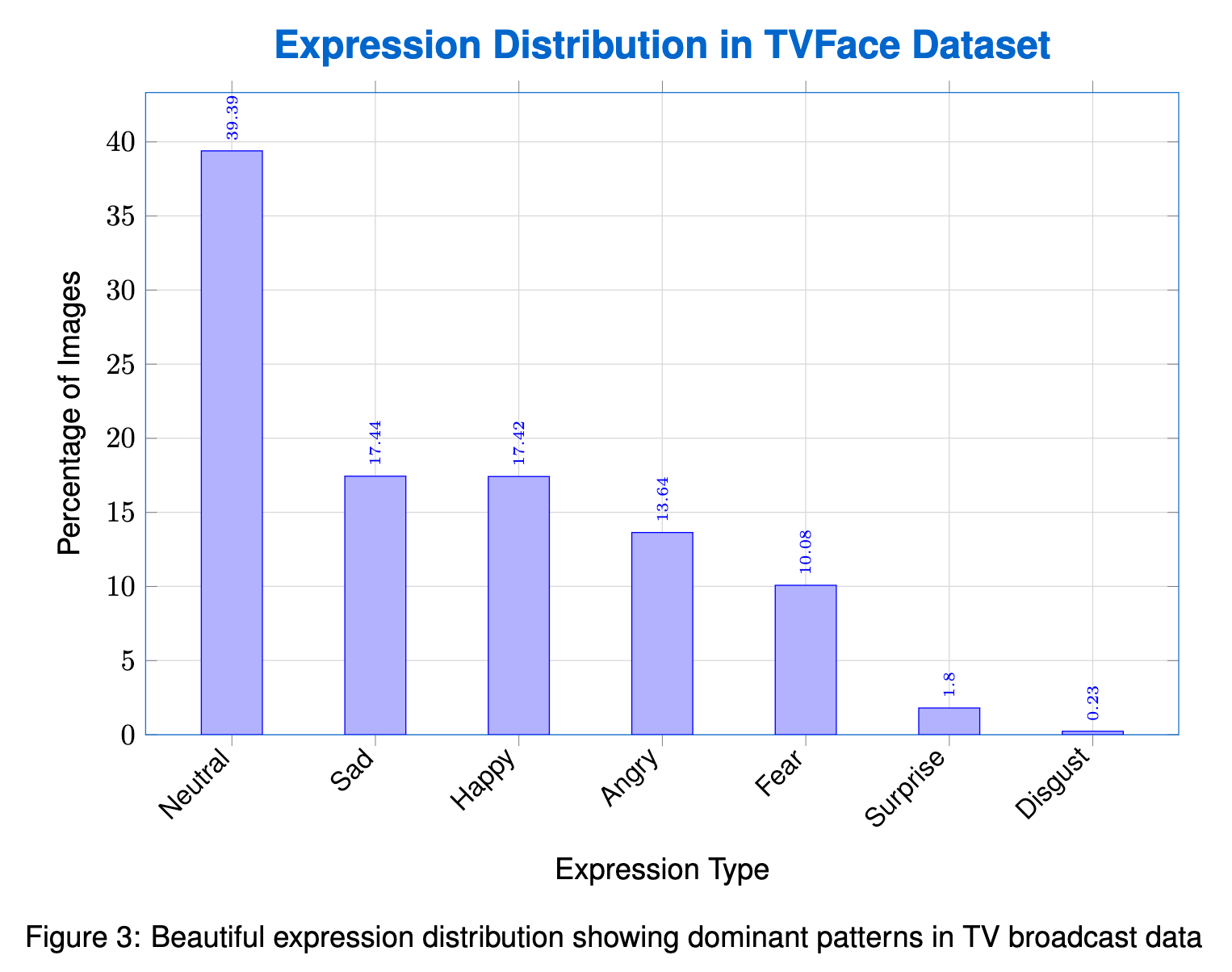
The release
The dataset
2.6M annotated face images across 28,955 identities, released for research.
Demographic labels
Probabilistic age, gender, ethnicity, expression, and head-pose annotations.
PyTorch loader
A TVFaceDataset class for drop-in use in recognition and clustering pipelines.
Peer-reviewed
Published in Springer's Pattern Analysis and Applications (2025).
Where it landed
A research resource for unsupervised facial clustering, large-scale recognition, and demographic-fairness analysis. Built at MachVIS and published in Springer's Pattern Analysis and Applications, under a Creative Commons non-commercial license.
It now anchors the TVFace Challenge 2026, a public clustering-and-retrieval competition built on the dataset.
Venue
Pattern Analysis & Applications
Year
2025
License
CC BY-NC 4.0 · research only
Portable lessons
01Real-world distributions beat clean ones for honest benchmarks.
02A long tail is a feature, not a defect, when you study recognition.
03Scale and ethics have to ship together.