Agentic AI · Game Engineering
VisionTactical
Two off-the-shelf LLMs play a 3D shooter on sight alone. No RL, no training, zero gradient steps.
Human perception, robotically.
VisionTactical is an autonomous agent that plays a custom 3D first-person shooter. It tests a simple idea: can off-the-shelf language models play a real-time game using nothing but sight and reasoning, with no reinforcement learning and no training at all?
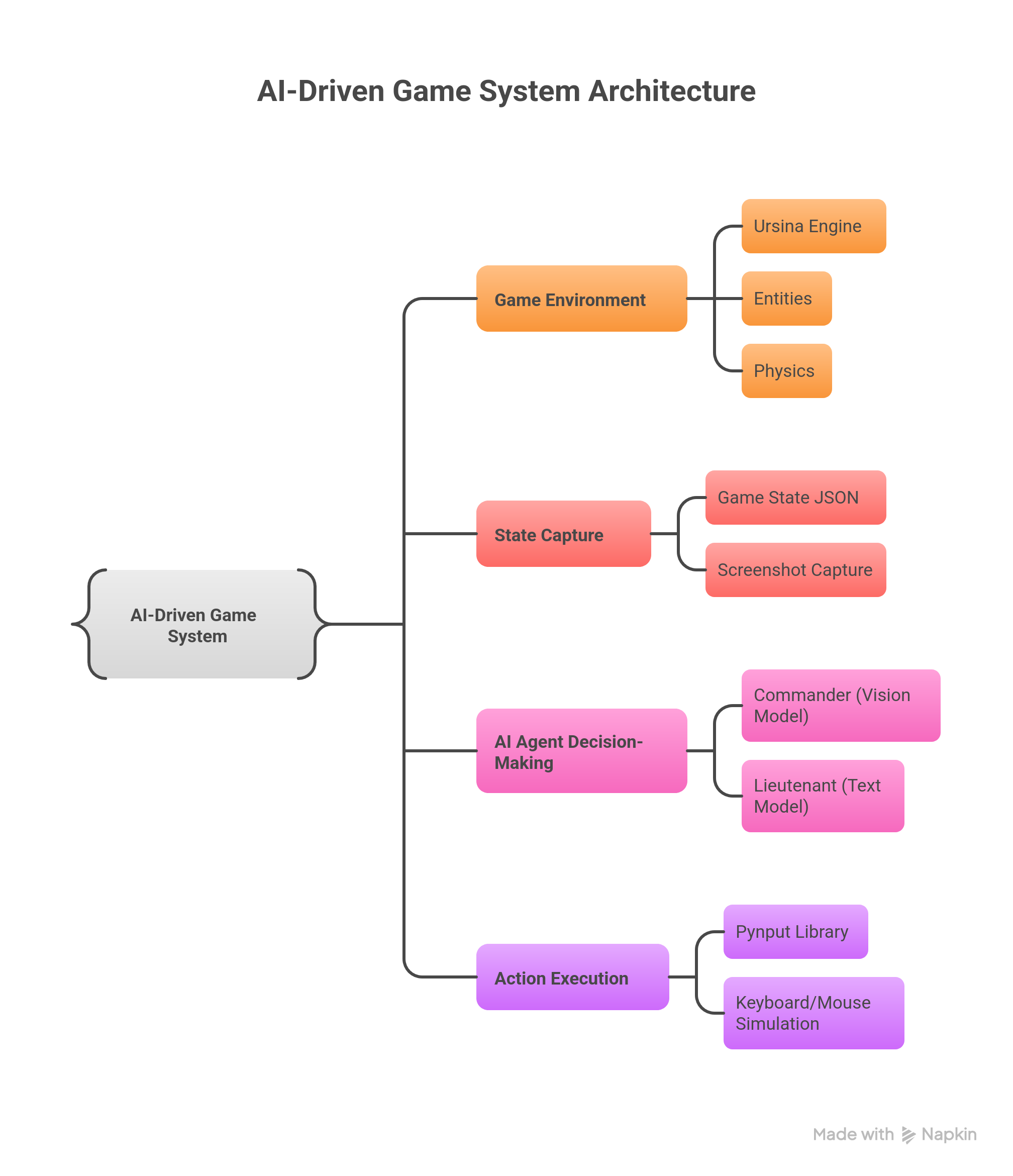
I built the game and the agents. The game is a 3D FPS in Ursina; the agents sit on top, perceiving the world through screenshots and JSON state and acting through simulated keyboard and mouse.
Real-time play, zero training budget.
Game-playing agents usually mean reinforcement learning: millions of frames, reward shaping, and a policy that only works in the world it trained on. I wanted the opposite: generality over a training loop, and a real-time control budget that two LLM calls have to fit inside.
A Commander and a Lieutenant.
Two roles. The Commander (Mistral 3.1), a vision model, looks at the screen and sets strategy from what it sees. The Lieutenant (DeepSeek V3), a text model, reads structured game state and turns the Commander's intent into the next concrete move.
The loop is deliberately simple: capture the screen and state, ask the Commander what's happening and what to do, ask the Lieutenant for the action, execute it with keyboard and mouse, repeat.
What shaped it
Split sight from tactics
- A vision model owns perception and strategy; a text model owns precise actions on structured state.
- Each model does what it's best at, and neither has to do both.
Own the whole stack
- I built the 3D game in Ursina so the agents had a world to act in, and the state schema they read.
- Screenshots via MSS, control via pynput. The agent uses the same inputs a human would.
No RL, on purpose
- No reward shaping, no training run, no fine-tune. Only prompting and a tight loop.
- The bet: frontier models already have enough world-model to adapt in-context.
Lose, then adapt, then win.
The whole thesis lives in two clips. First the agent gets demolished by a single enemy: the loop runs, but the strategy is wrong. Then, with the same models and no retraining, it reads the situation differently and wins. Adaptation without a single gradient step.
The system
Custom 3D FPS
A first-person shooter built in Python + Ursina, with a clean state schema.
Commander (vision)
Mistral 3.1 reads the screen and sets strategy.
Lieutenant (text)
DeepSeek V3 turns intent into the next keyboard/mouse action.
Perceive-act loop
MSS screen capture in, pynput control out. Open-sourced under MIT.
Where it landed
A working proof that two prompted models, split by role, can play a real-time 3D game and adapt across attempts. Built end to end, game included.
Training
None, prompting only
Agents
Vision + text, 2 roles
Code
Open source · MIT
Portable lessons
01Split the problem by what each model is best at.
02Perception plus reasoning can replace a training loop.
03Give an agent the same controls a human has, and it adapts.